This is a guest posting by Peter G. Walen.
Many high-profile testers react negatively to most metrics programs. They argue that measurements usually do not measure the things intended. They point out that people change their behavior to drive the metrics in the direction management wants to see. These make it very easy to get the wrong idea about what is happening when reading a number with no other information.
Development managers and leaders still need to understand what is happening on a project at a high level. There are metrics that can be beneficial for both management and the testing team. Here are a couple of the measurements that I have found to be useful.
Test Coverage
Understanding test coverage is useful because it gives you ideas about what has been tested and what has not. This metric can help answer the question of how much longer you need before you’re done testing. It may show why a bug was not caught. It can also show why testing is taking so long and whether we are testing the right things.
My preference is to take a holistic approach. Start with the easiest place to measure first: the codebase. Adding a code coverage tool to your continuous integration system will give an idea of how much of your codebase is covered by unit tests. This may not be useful at a glance, but over time you will see trends. If unit test coverage is dropping, then you might also see an increase in time spent by your testers on bugs that could have been designed out of the product earlier on.
You also want to understand testing performed by people with less tooling. A useful tip for this is making product inventories. We talk about software through abstractions all the time — pages, features, scenarios, configurations. Start keeping track of these metrics in some lightweight format that’s easy to change and share. This coverage can be reviewed in a way similar to how code-level coverage is reviewed.
Test coverage by itself doesn’t tell you about the quality of your testing or whether you’re designing tests that are likely to find an important problem. It does give you a place to start the conversation. The goal in talking about test coverage is to show what is in the plan, review what is already covered, and see what is missing.
Rework
Rework is what happens when something isn’t done quite right the first time around. Tracking rework looks at things that surround testing and directly affect it.
Bugs are usually the first piece of evidence. For example, a new change gets merged into the test branch. When we start looking closely, we find that submitting the page fails under a few different conditions. We then have to spend time investigating and collecting the errors, reporting bugs, and then waiting for the fix to be merged back and built. Hopefully, things work the second time around, but sometimes they don’t.
This can also happen before development starts. One company I worked with did a Three Amigos meeting before any work began on a change. This was to make sure we all understood what change was being requested and had one last opportunity to decide whether we were building the right thing. A few times a month, we would get a new card and start talking about it. Eventually, we would discover that it somehow conflicted with a feature we were already working on, or that some aspect of the change wasn’t clear enough to start on. That card had to go back into the product management queue of work to review and clarify. It was a good thing that this happened because otherwise, the development team would have spent time on the wrong thing. But it still represents rework.
Rework is usually found by testers, but it tells a story about the development environment. When rework happens frequently, it usually means that people with the right skill set are missing from the team, or that time constraints are so short that other aspects of the product are being sacrificed to get the product built “faster.”
Each bit of rework affects the schedule and has a cascading impact on the things that are supposed to come next. They also affect the budget, because each of these instances means more people are working longer than was initially planned for.
The easiest way to begin tracking rework is to measure bugs and cards that move backward in the flow. The point of this is not to count bugs or to see how long it takes you to test something. The intent is to learn what it is in the environment that causes large numbers of bugs or lots of false starts. This shows us how the situation can be improved by skill development or removing project constraints.
Regression Problems
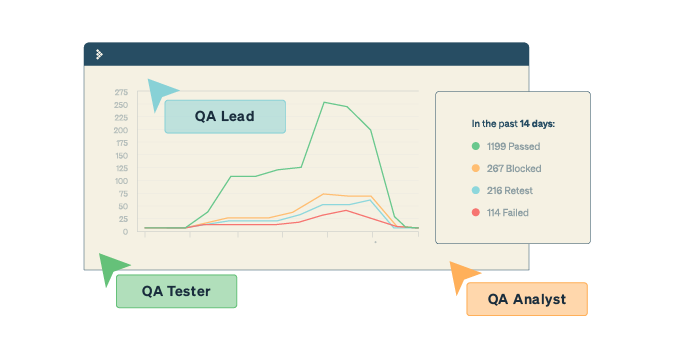
Counting and measuring problems found during regression testing is a specific form of measuring rework. I find it helpful when evaluating how ready an application is for release to acceptance testing or production.
Evaluating regression bugs says less about the work the test team is doing and more about development practices or environment. Like most metrics around testing or software quality, they are trailing indicators for development methods and practices. When regression testing turns up occurrences of bugs found, fixed, and tested earlier in the development process, these can point to problems.
When regression testing is done in an environment other than the main testing location, they are a measure of the effectiveness of deployment processes as well as development. They alert you to problems in configuration, data structures, and other environmental differences that need to be addressed or reviewed before releasing them to the production environment. Unfortunately, these can be among the most costly problems to solve before releasing to production.
Measurement Drives Behavior
People change their behavior to make a metric move the “right way.” Sometimes this is done on purpose, and sometimes it is subconscious (Goodhart’s law). Measurements you choose to consider need to help you understand specific problems. Using them as information points and not performance or behavioral expectations will ease tensions. Communicate the measurements and the purpose clearly.
It can be tempting to reward people who find the most problems or developers with the fewest bugs in their code. I have generally found this to be counterproductive and does more harm than good. Experienced developers take on the most complex and challenging tasks, increasing the odds of problems being found. Better testers will take their time and dive well into the behavior of the software and system as a whole. They may not find as many bugs as someone blowing through the application finding smaller, cosmetic issues. They may find problems that impact the behavior of the software and the experience of the customers using it.
Start with a problem that impacts the team, organization, or customers. Find ways to measure things around that problem. Let the team know the purpose and why this matters. Let the measurement itself help drive good behavior.