This is a guest post by Matthew Heusser.
A while ago I was managing a programmer I’ll call Paul. The job was set. The software was determined. The domain was a little bit different – this was contract work and there were more than a few dependencies outside the team. I asked Paul when he would be done with the work, and he said as soon as possible. Asked when that would be, he would shrug his shoulders. So I worked the other way — what could he have done by the end of the quarter, by the end of the month … by the end of the week? In theory, the tighter the timebox, the easier it should be to make accurate estimates. Eventually, Paul expressed some hope to compile a few of the simpler tasks. That was not a promise; it was a hope. Another colleague told me that he simply refused to give any estimates until he had the core of the engineering problem solved. A third, my first mentor, told me that if he had delayed that long, he was probably about a third done, and he could project estimates from there.
Can’t we do better?
Seriously. Can’t we do better?
Today I will tell a few stories about how I have done better.
An automation project
A few years ago I helped a company do a test automation proof of concept. It was your typical proof of concept with all warts and problems. There were data setup problems and problems getting it to run on different browsers, and problems getting it to run in the Continuous Integration server, and problems connecting the bing boing to the flirb flob with an RSS twinkle. We had these ideas split into “stories” where each story represented a feature. It was a lot of unknowns, a lot of two steps forward and five steps back, what I might call true Research and Development. This was more than a bit like the work Paul was doing for me, just one roadblock after another. We knew what they were and we had a list, and some things would take two hours to figure out and some things might take a week.
So there we are, in the management meeting, asked to give status, and our supervisor is asking when we’ll be done with the demo. My colleague Sandy is saying that they don’t know, and talking about the flirb flob and the bing bong. The manager doesn’t care, or at least, isn’t into the details. Every time we get close to a commitment, Sandy hesitates and says it depends, makes a bunch of assumptions, then lists an engineering problem.
It’s time for me to speak, so I try a different tactic.
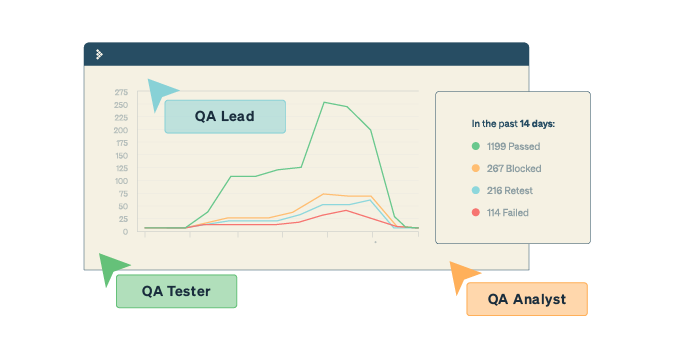
“Well, we have about forty things to do. We’ve done about twenty in the past two weeks. Assuming our future challenges are as complex as the current challenges, we should be done in about a month. Today is the 15th of October, October has thirty-one days, no holidays are coming– let’s aim for the 15th of November. We’ll keep you updated on progress at least weekly.”
That was it. The manager could breathe easy and go back to his other fires. As it turned out, we did meet that deadline and did do a demo and did succeed.
Two things to notice about my assumptions here. First, I assume the data will have what’s called a standard distribution, or sometimes a bell curve. That is, that the effort involved in the stories will average out. Second, I covered it by framing the one-month “deadline” as not a deadline but a goal. Over time we would get more data, so our projections should get more accurate.
There are plenty of more complicated models you can use to predict, even to the point of calculating confidence intervals. You don’t need Machine Learning for this; Troy Magennis has an excellent Spreadsheet-based tool. You could be more confident, for example, by selecting only the slower stories for your sample to predict from. This is basically like saying “Even if all the stories average as slow as our 30% slowest stories, then we’ll be done within six weeks.”
When you start to see work this way, suddenly the world transforms. You see data everywhere. If you are building a bridge, you want to know how many bricks it will take and how many bricks you are using a day so you can predict when you’ll be done building the bridge.
Until it, all stop working.
Construct validity
I’m not sure what the landmark article on Software Engineering measurement is, but if you were looking at prerequisites, of things you should read before diving in, Dr. Cem Kaner’s Software Engineering Metrics: What Do They Measure and How Do We Know? should certainly be on your shortlist.
Kaner points out that what you measure matters. For example, let’s say you count the number of bills on a table. What you want is value. If you don’t know the denomination, then counting the number of bills means very little. Anyone who does know the amounts could “split the table” with you and walk away with ten or twenty times as much as you have. The story seems absurd, but when you apply it to, say, counting bugs, or lines of code, or even stories to get to productivity, you start to understand that people (and even nature itself) can exploit the difference between what you want (testers rewarded for finding problems) and what you measure (bug count). Another colleague of mine, Jess Lancaster, once remarked that he could tell the job candidates that “came up” through the crowdsourced testing community. According to Jess, they tend to look for the big obvious bugs quickly, as those are easy to find and get much more reward per minute expended than complex business-logic or user-interaction problems.
The risk for prediction is that we don’t have that bell curve, or that the things we slice up are not of equal size. That makes our predictions inaccurate. In my experience, software leaders love a “sure thing”, and will sometimes reward people who are confident and wrong over those that are uncertain and right.
Moving forward
During the CMM Craze of the 1990s, many companies were interested in getting to “Level 4”, where they could predict defects and performance. As it turns out, predicting defects just isn’t that hard. The spirit of the CMM was to do things the same, so the bricks were all the same size, to make prediction possible. As it turns out, that actually works. The problem is that it pushes you to do the same thing over and over again. Interesting Software Engineering doesn’t work that way. If you’re building the same thing, you should abstract the prior project to a code library and only implement what is new and different.
There is some potential to do prediction on defects, combined with analysis, and most importantly, prevention. What amazes me is how few organizations do it.
Think about that for a moment.
The tools and approaches I mentioned provide reliable help in making predictions on everything from delivery to defects. Remove the emphasis on deadlines and shift to goals while gathering data to inform decisions. Use the benefits from reevaluated CMM and apply them to abstract code libraries and better identify risk, then you can start to predict defects.
Matthew Heusser is the Managing Director of Excelon Development, with expertise in project management, development, writing, and systems improvement. And yes, he does software testing too.